
Část #3: Modulární systémy ve Spring Framework
V prvním díle jsme si ukázali, jak jednotlivé moduly separovat a propojit ve stromu. V předchozím pak způsob, jak strom udržet konzistentní a refreshovatelný za běhu aplikace. Dnešní díl bude o tom, jak jednotlivé moduly mezi sebou propojit - respektive, jak zajistit interakci mezi jednotlivými moduly.
Vystavení "interface" bean modulů
Pokud se vydáte cestou tvorby stromu z aplikačních kontextů, pravděpodobně narazíte na problém rozhraní jednotlivých modulů. Vraťme se k našemu příkladu reportovacího modulu, modulu uživatelů a web aplikace. Jak vyřešit velmi pravděpodobný usecase, kdy z web aplikace budeme chtít v reportu zobrazit seznam uživatelů? Jedná se o propojení všech třech modulů, které jsou nezávislé (mají oddělené životní prostory a jeden nevidí k druhému) a které jsou ve stromu na stejné úrovni - podřízené stejnému root contextu.
Tuto záležitost lze řešit kombinací BeanPostProcessoru a anotací nebo použitím marker interfacu (popř. zavedením vlastního namespace handleru - nové fíčurky springu od verze 2.X). Do aplikačního kontextu zaregistrujeme BeanPostProcesor, kterému do konstruktoru vložíme odkaz na root kontext. Tento post procesor každou beanu po inicializaci prověří na přítomnost anotace (nebo implementaci marker interfacu), a pokud vyhovuje dané podmínce, zaregistruje tuto beanu jako singleton v root kontextu s pomocí metody registerSingleton dostupnou na bean factory aplikačního kontextu.
Výřez BeanPostProcessoru, který toto zajišťuje je zobrazen v následujícím příkladu:
/**
* This postprocessor exports all beans marked as ModulePublicInterface into root CPS
* application context.
*/
public class ModulePublicInterfacePostProcessor implements BeanPostProcessor {
private static Log log = LogFactory.getLog(ModulePublicInterfacePostProcessor.class);
private AbstractRefreshableApplicationContext rootContext;
public ModulePublicInterfacePostProcessor(AbstractRefreshableApplicationContext rootContext) {
this.rootContext = rootContext;
}
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if (bean instanceof ModulePublicInterface) {
if (log.isInfoEnabled()) {
log.info("Exporting module public interface bean: " + beanName);
}
DefaultListableBeanFactory rootFactory = (DefaultListableBeanFactory)rootContext.getBeanFactory();
rootFactory.registerSingleton(beanName, bean);
}
return bean;
}
}
BeanPostProcessor testuje beany na implementaci jednoduchého marker interfacu:
/**
* Marker interface signalizing, that class of this type could be used as public intefrace
* of particular module. ModulePublicInterfacePostProcessor exports all beans
* with this marker to root application context, so they are reachable by any
* other modules or web application contexts.
*/
public interface ModulePublicInterface {}
Při refreshi aplikačního kontextu následujícího inicializovaného modulu již dokáže tuto beanu Spring automaticky nasetovat (respektive, vy jste schopni ji dynamicky voláním metody getBean v aplikačním kontextu takového modulu získat). Pak už je důležité se jen vyvarovat cyklických závislostí mezi moduly a zajistit, aby se moduly inicializovaly ve správném pořadí. Celý princip je možné ukázat na popisu inicializační sekvence našeho ukázkového příkladu:
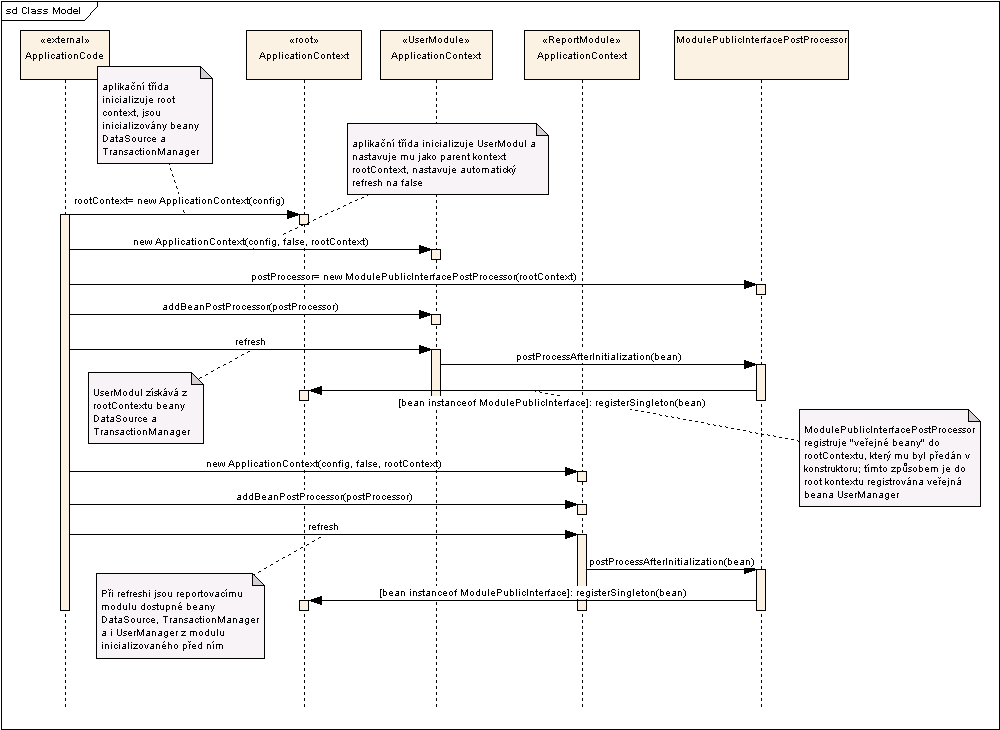
Tímto principem neporušujeme zapouzdřenost daného modulu - moduly jsou stále oddělené a mají své životní prostory. Pouze výběrově zpřístupňujeme beany, které tvoří rozhraní modulu. Beany rozhraní jsou již správně inicializované, takže z programového hlediska nemusíme už nic dělat - stačí nechat Spring aplikaci kompletně sestavit. V sekvenčním diagramu je naznačeno, že kompozici jednotlivých modulů s root kontextem zajišťuje "aplikace" - nicméně i tuto část můžeme nahradit Springem. Pokud v konfiguračním souboru springu uvedete deklaraci beany, která je aplikačním kontextem, zajistí vytvoření a propojení oddělených spring kontextů sám Spring. Registraci bean post procesorů opět může zajistit Spring - pokud najde beany typu BeanPostProcessor v konfiguraci automaticky je použije.
Testovat moduly je možné aniž by ke svému běhu potřebovaly mít nahozenou celou infrastrukturu. Při testech pouze modulu "dohodíme" chybějící beany, které modul vyžaduje od svého okolí (např. dataSource z root kontextu). Místo bean rozhraní ostatních modulů můžeme v testech použít mock beany - popřípadě můžeme dané beany označit jako lazy-init="true", takže pokud si na ně test vyloženě nesáhne (nebo je nebude vyžadovat jiná ne-lazy beana) vynechá je Spring z inicializace a tudíž mu ani nebude vadit, že nemá dostupnou beanu, kterou si přejete injektovat.
BeanPostProcessor vs. BeanFactoryPostProcessor
Musím uvést výše uvedený sekvenční diagram na pravou míru. Aplikační kontext jako takový neakceptuje BeanPostProcessory (jak je pro zjednodušení zakresleno v diagramu), ale pouze BeanFactoryPostProcessory. Jsou to dvě rozdílná rozhraní, která mají rozdílný kontrakt.
BeanFactoryPostProcessor: implementace tohoto rozhraní lze zaregistrovat pouze na aplikačním kontextu a aplikační kontext je zavolá ve chvíli, kdy je inicializována BeanFactory avšak před tím, než BeanFactory instanciuje jednotlivé beany - rozhraní slouží k "modifikaci" inicializované BeanFactory před tím, než se zprocesují beany z konfigurací této BeanFactory
BeanPostProcessor: implementace tohoto rozhraní lze zaregistrovat pouze na BeanFactory a rozhraní je voláno po vytvoření a "nasetování" instance každé beany v konfiguraci dané BeanFactory, implementace BeanPostProcessoru mohou tedy volně nakládat s zinicializovanými beany ihned po jejich vytvoření
Z výše uvedného vyplývá, že není možné na aplikačním kontextu přímo zaregistrovat námi požadovaný ModulePublicInterfacePostProcessor. Ani není možné zavolat si getBeanFactory a aplikačním kontextu před jeho refreshem (vyletí vyjímka signalizující, že kontext není připraven). Po refreshi už je nám to zase na nic, protože PostProcessory po refreshi už nezaberou (museli bychom znovu zavolat refresh, což je zbytečné).
Problém lze vyřešit obalením BeanPostProcessoru do BeanFactoryPostProcessoru, jak je naznačeno v následujícím příkladě:
/**
* BeanFactoryPostProcessor, that can register BeanPostProcessors to BeanFactory just in time BeanFactory prepared to accept them.
*/
public class DelayedBeanPostProcessorRegistrator implements BeanFactoryPostProcessor {
List beanPostProcessors = new ArrayList();
public void addBeanPostProcessor(BeanPostProcessor bpp) {
beanPostProcessors.add(bpp);
}
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
for(int i = 0; i < beanPostProcessors.size(); i++) {
BeanPostProcessor beanPostProcessor = (BeanPostProcessor)beanPostProcessors.get(i);
beanFactory.addBeanPostProcessor(beanPostProcessor);
}
}
}
Co bude v dalším díle?
V minulém článku jsem sice původně avizoval, že tento díl bude poslední, nicméně se ukázalo, že by byl přeci jenom trochu dlouhý. Proto vás čeká ještě jeden, teď už opravdu poslední díl. V něm proberu druhou část rozhaní modulů a tou jsou aplikační události. Aplikační události jsou jedním ze základních stavebních kamenů Springu a proto by bylo škoda se ochudit o tuto skvělou vlastnost na rozhraní modulů. Je zřejmé, že nebudeme chtít otevřít všechny aplikační události svému okolí, nicméně u řady událostí bychom chtěli umožnit ostatním modulům reagovat. Jako příklad uvedu interakci mezi modulem pro správu uživatelů a notifikačním modulem - notifikační modul se stará o rozesílání emailových notifikací v reakci na konkrétní aplikační události (samozřejmě obecně - konfigurovatelně). To je typická ukázka stavu, kdy chceme, aby uživatelský modul dokázal emitovat třebas událost "založení nového uživatele" tak, aby notifikační modul mohl reagovat odesláním emailu.