Nevím jak vám, ale nám se při vývoji často stává, že vývojáři některé věci přehlíží a to se nám negativně odráží na produktivitě a kvalitě výstupu. Člověk je tvor omylný, ale inteligentní a proto se snaží se vybavit takovými nástroji, které jeho nedokonalosti dokáží vyvážit. Na posledním hackathonu kolega
Michal Kolesnáč přišel s nápadem a prototypem rozšíření našeho
existujícího doplňku pro Google Chrome, které pomocí
HTML 5 notifikací upozorní vývojáře na potenciální problémy na prohlížené web stránce. Minulý týden jsme řešení dotáhli do konce a myslím, že stojí za to, abych se s Vámi o tento nápad podělil.
Na úvod se podívejte, jak nám výsledné řešení pomáhá v praxi:
[youtube=https://www.youtube.com/watch?v=dluseSIN3tU]
Princip fungování
Princip je relativně obecný a je určitě přenositelný i do vašeho vývojového ekosystému. O vývoji rozšíření pro Chrome toho už bylo
napsáno i v češtině docela dost a proto zde nepůjdu do úplných podrobností.
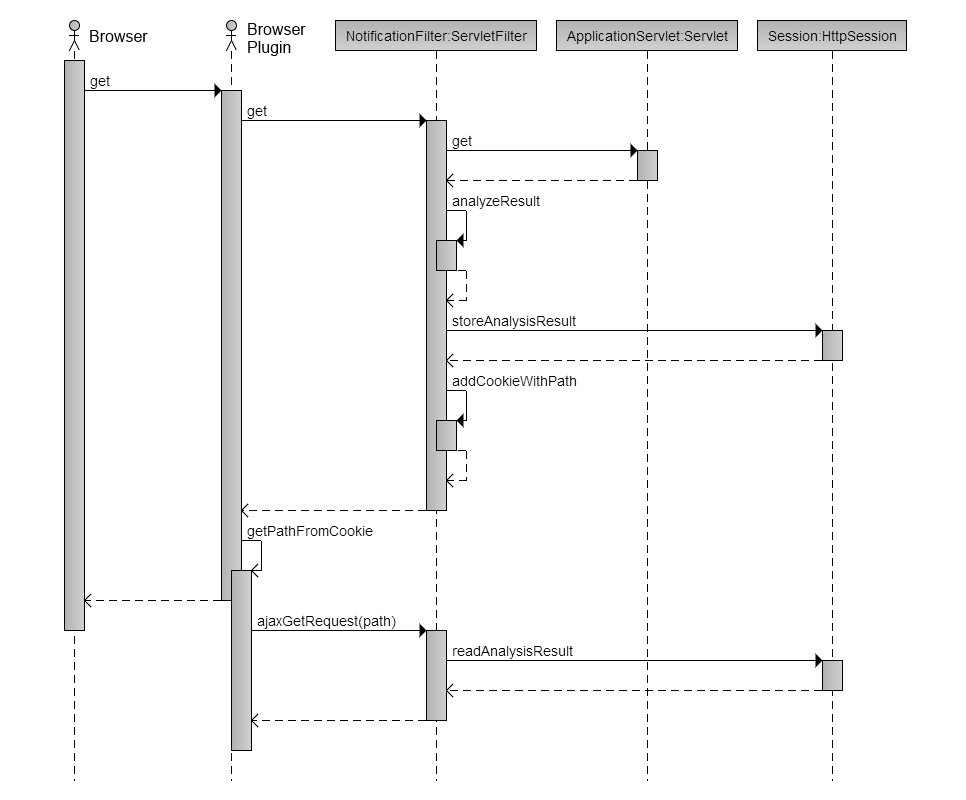
Celý princip je zachycen na následujícím sequence diagramu (btw. vytvořený v
http://www.ckwnc.com/ ... což je krásná služba pro generování sequence diagramů - jen nedoplňuje popisky k aktorům):
Jednoduše řečeno - každý požadavek na webovou aplikaci prochází servletovým filtrem, který při každém požadavku vygeneruje unikátní token a zapíše do hlaviček odpovědi cookie obsahující URL, na kterém bude v budoucnu odpovídat na požadavky pro zobrazení zpráv spojených s tímto requestem. Po ukončení zpracování HTTP požadavku filtr zanalyzuje aktuální stav aplikace a případně zapíše zprávy pro vývojáře ohledně věcí, kterým by měl věnovat pozornost.
Chrome plugin monitoruje změny cookies a pokud narazí na změnu v cookie se sledovaným názvem, vybere z ní URL, vytvoří XmlHttpRequest a AJAXem se dotáže serveru na seznam zpráv k zobrazení. Požadavek zachytí opět náš servletový filtr, podle unikátního tokenu si ze session vytáhne dříve vygenerovaný seznam zpráv. Nakonec vytvoří JSON zprávu s odpovědí, která obsahuje buď prázdné pole, nebo seznam notifikací s dodatečnými informacemi (např. důležitostí sdělení). JSON je pluginem rozparsován a uživateli jsou prezentovány zprávy jako HTML 5 notifikace. Je důležité si uvědomit, že najednou mohou být zobrazeny pouze 3 notifikace (omezení prohlížeče) a proto je potřeba ty zprávy koncipovat spíše jako odkazy někam dál. V našem případě otvírám po kliknutí na notifikaci
RamJet Inspektor, kde je k nalezení už konkrétní rozpad problému.
Cílem rozhodně není zahltit vývojáře informacemi - notifikace mají zobrazovat jen informace o důležitých problémech, které vyžadují pozornost a je riziko, že by je vývojář mohl přehlížet. Naopak pokud by je chtěl přehlížet, tak by mu měly notifikace jeho ignoranci alespoň znepříjemnit :).
V našem případě aktuálně monitorujeme tyto problémy:
- pomalá odezva stránky (více jak 1 vteřina na vrácení kompletního výstupu)
- pomalé SQL dotazy při zpracování požadavku (více jak 200ms na zpracování SQL příkazu)
- duplicitní SQL dotazy (špatné použití cachování)
- chyby při zpracování stránky (jak při akci, tak i v rámci renderingu) - obvykle by měly být vidět samy od sebe, ale někdy se skryjí ve <script> blocích nebo na stránce chybí komponenta pro výpis chybových hlášení
- chyby při aplikaci změn v konfiguraci (refresh Spring kontextů selhal) - jelikož se jede z poslední známé funkční konfigurace, vývojář často problém s reloadem nepostřehne a marně pátrá proč se aplikace nechová tak, jak by podle poslední konfigurace měla
- (zvažujeme) použití deprekovaných komponent a funkcí
- (plánujeme) zobrazení informace o nelokalizovaných textových popiscích na stránce
A také tyto významné informace v životním cyklu aplikace:
 Ve Forrestu jsme jako verzovací systém používali po velmi dlouhou dobu prastaré CVS. Respektive v době, kdy se s tím ve firmě začínalo (pamětníků už je jen hrstka) to zase až taky zastaralý systém nebyl (mluvíme o roku 2000). Dlouhou dobu jsme zvažovali náhradu za nějaké modernější VCS, ale nikdo se toho nechtěl osobně ujmout a byla tady celá řada překážek, se kterými bychom se museli kvůli přechodu vypořádat. Kromě infrastruktury (háčky do issue trackeru, build a install skripty, zálohování atd.) jsme měli obavu i o to, jak by přechod zvládly ty desítky vývojářů, kteří CVS používají - kritické místo se nám zdál tým webmasterů starající se o drobné úpravy na existujících projektech (v řádu desítek úprav denně). Prostě jsme hledali výmluvy, protože se nám do migrace nechtělo - zvlášť, když jsme neměli uvnitř firmy nikoho, kdo by nějaké nové VCS evangelizoval.
Ve Forrestu jsme jako verzovací systém používali po velmi dlouhou dobu prastaré CVS. Respektive v době, kdy se s tím ve firmě začínalo (pamětníků už je jen hrstka) to zase až taky zastaralý systém nebyl (mluvíme o roku 2000). Dlouhou dobu jsme zvažovali náhradu za nějaké modernější VCS, ale nikdo se toho nechtěl osobně ujmout a byla tady celá řada překážek, se kterými bychom se museli kvůli přechodu vypořádat. Kromě infrastruktury (háčky do issue trackeru, build a install skripty, zálohování atd.) jsme měli obavu i o to, jak by přechod zvládly ty desítky vývojářů, kteří CVS používají - kritické místo se nám zdál tým webmasterů starající se o drobné úpravy na existujících projektech (v řádu desítek úprav denně). Prostě jsme hledali výmluvy, protože se nám do migrace nechtělo - zvlášť, když jsme neměli uvnitř firmy nikoho, kdo by nějaké nové VCS evangelizoval.
 Po 3 letech dělám větší refaktoring na našem direct mailingovém modulu a jako první jsem se rozhodl povýšit verze knihoven a zrefaktorovat JUnit testy, které jsou tam ještě psané ve stylu JDK 1.4.
Po 3 letech dělám větší refaktoring na našem direct mailingovém modulu a jako první jsem se rozhodl povýšit verze knihoven a zrefaktorovat JUnit testy, které jsou tam ještě psané ve stylu JDK 1.4.
V souvislosti s tím jsem samozřejmě přepracoval formu testů z dědičné hierarchie na anotace, které byly představeny poprvé ve Spring 3.X (pokud se nepletu). A tu jsem zjistil, že mám drobný problém - v původní verzi mého kódu jsem využíval dynamické kompozice Springového kontextu k tomu, abych stejné integrační testy pustil proti různým implementacím úložišť dat (paměť, MySQL databáze, Oracle databáze ...). V aktuální verzi Springu se ale v anotaci @ContextConfiguration uvádí statický výčet konfiguračních XML a to situaci komplikuje.
 Nedávno jsem jedním svým twítem vyvolal menší diskusi ohledně toho, co nám dovoluje komponentový framework oproti tomu, čeho bychom byli schopni dosáhnout s jednoduchým MVC rámcem. Bohužel twitter mi nedává takovou možnost vyjádřit se a tak jsem chtěl důvody a výhody, které vidím v komponentách na frontendu, popsat trošku obšírněji v tomto článku.
Nedávno jsem jedním svým twítem vyvolal menší diskusi ohledně toho, co nám dovoluje komponentový framework oproti tomu, čeho bychom byli schopni dosáhnout s jednoduchým MVC rámcem. Bohužel twitter mi nedává takovou možnost vyjádřit se a tak jsem chtěl důvody a výhody, které vidím v komponentách na frontendu, popsat trošku obšírněji v tomto článku.
Komponentový model na webové vrstvě přináší oproti MVC se "standardním" šablonovým systémem možnost elegantní znovupoužitelnosti částí, které se znovu použít dají. Pro mě jako vyznavače DRY je toto jedna z VELKÝCH výhod. Namítnete, že znovupoužitelnosti se přeci dá dosáhnout i v běžném šablonovacím systému - co třeba JSP tagy nebo Freemarkerová makra? Touhle cestou jsem si prošel a výsledek byl vždycky kostrbatý - obvykle se vám podaří znovupoužít buď vykreslovací šablonu nebo aplikační logiku, ale nikdy ne rozumně obojí.

Tento článek bude krapet filozofického ražení a nese zvláštní ale snad výstižný název, jak se pokusím vysvětlit dále. Nelehko se popisuje, co myslím tím výrazem „spád“ – v češtině bych mohl použít i podobně zabarvená slova jako třeba bzukot, mravenčení nebo vzruch, z cizích jazyků bych si vypůjčil výrazy jako je trakce nebo momentum. Určitě pochopíte, co mám na mysli, když poukážu na živé a prosperující komunity, které známe z našeho okolí. Spádem myslím stav, kdy se okolo vás děje pořád něco nového, něco co vás obohacuje, nabíjí vás energií a vnitřně vás nutí se do víru také přidat.
 O radosti z releasů jsem tady na blogu psal už dříve a teď budu psát znovu, ale z jiného úhlu pohledu. Téměř po roce od začátku analytických prací jde do produkce jeden z mých největších dosavadních projektů - Ok Bonus portál pro slovenskou společnost DOXX. Podstatou projektu je poskytnout technické řešení maloobchodům a jednotlivcům pro tvorbu věrnostních (bonusových) programů, které si dokáží ušít samy sobě na míru.
O radosti z releasů jsem tady na blogu psal už dříve a teď budu psát znovu, ale z jiného úhlu pohledu. Téměř po roce od začátku analytických prací jde do produkce jeden z mých největších dosavadních projektů - Ok Bonus portál pro slovenskou společnost DOXX. Podstatou projektu je poskytnout technické řešení maloobchodům a jednotlivcům pro tvorbu věrnostních (bonusových) programů, které si dokáží ušít samy sobě na míru.
Řešení je složeno z několika částí: desktopové aplikace postavené nad NetBeans RCP - tzv. terminálu, který bude provozován vedle pokladního systému a bude umožňovat zápis informací o nákupech a také čerpání odměn. Nákupy a bonusy se evidují na libovolnou NFC kartu, kterých v současné době po světě běhá více než dost (samozřejmě bude možné získat u provozovatelů systému i brandované Ok Bonus NFC karty). Druhou část představuje tzv. "platební brána", která zpracovává transakce ze všech desktopových klientů a spravuje zákaznické účty. Třetí část je potom webový portál Ok Bonus, který představuje prostředníka mezi zákazníky, obchodníky a platební branou. Na portále jsou k dispozici výpisy z účtů (tj. evidence nákupů, přidělování bonusů atd.), pro obchodníky potom rozhraní pro tvorbu bonusových programů, správu autorizovaných karet a terminálů, statistiky, e-shop a vyúčtování.
 Jestli ano, tak by mne velmi zajímalo, jak to děláte. My jsme totiž ještě donedávna žádnou jistotu neměli - vše záleželo na poctivosti a důslednosti programátorů. Jenže v Javě není tahle záležitost vůbec jednoduchá a tak vám může díky nějaké referenci hluboko ve stromu objektů uniknout, že to, co ukládáte do session, má vazbu na objekt, který serializovatelný není. Výsledkem je ztráta session při restartech aplikačního serveru nebo zamezení možnosti session replikovat mezi nody clusteru.
Jestli ano, tak by mne velmi zajímalo, jak to děláte. My jsme totiž ještě donedávna žádnou jistotu neměli - vše záleželo na poctivosti a důslednosti programátorů. Jenže v Javě není tahle záležitost vůbec jednoduchá a tak vám může díky nějaké referenci hluboko ve stromu objektů uniknout, že to, co ukládáte do session, má vazbu na objekt, který serializovatelný není. Výsledkem je ztráta session při restartech aplikačního serveru nebo zamezení možnosti session replikovat mezi nody clusteru.
 Škálování databází je velké téma a já rozhodně nejsem takový odborník, abych tady rozebíral kdovíjaké detaily. Zcela jistě znáte termíny jako je sharding, o kterém psal Dagi už před 5 lety, popřípadě znáte termín partitioning, který nám nabízejí některé DB stroje "zadarmo" a jiné "za peníze". Alternativním způsobem horizontálního škálování je škálování pomocí sady replik pro čtení, o kterém lze uvažovat v případě, že máte aplikaci, které řádově méně zapisuje do databáze než z ní čte. Konkrétně se jedná o to, že máte několik databázových strojů v režimu MASTER-SLAVE(S), který se často nasazuje už jen z důvodu hot-backupu (tj. v případě výpadku master databáze je možné velmi rychle z repliky učinit nový master a pokračovat v běhu aplikace).
Škálování databází je velké téma a já rozhodně nejsem takový odborník, abych tady rozebíral kdovíjaké detaily. Zcela jistě znáte termíny jako je sharding, o kterém psal Dagi už před 5 lety, popřípadě znáte termín partitioning, který nám nabízejí některé DB stroje "zadarmo" a jiné "za peníze". Alternativním způsobem horizontálního škálování je škálování pomocí sady replik pro čtení, o kterém lze uvažovat v případě, že máte aplikaci, které řádově méně zapisuje do databáze než z ní čte. Konkrétně se jedná o to, že máte několik databázových strojů v režimu MASTER-SLAVE(S), který se často nasazuje už jen z důvodu hot-backupu (tj. v případě výpadku master databáze je možné velmi rychle z repliky učinit nový master a pokračovat v běhu aplikace).
 Do you use Commons File Upload library in your application? Do you use DiskFileItemFactory for storing big files to a temporary disk storage? Do you use FileCleaningTracker to get rid of unused temporary files as it is recommended in documentation?
Do you use Commons File Upload library in your application? Do you use DiskFileItemFactory for storing big files to a temporary disk storage? Do you use FileCleaningTracker to get rid of unused temporary files as it is recommended in documentation?
If so you probably have a memory leak in your application you don't know about.
Stored files are meant to be cleared when there is no reference to the FileItem instance created by this library. Or at least this is stated in the documentation:

 Po delší přestávce jsme zavítali do kanceláří RSJ poblíž pražského Florence. Společnost se zabývá algoritmickým obchodováním na světových burzách a bylo o ní slyšet v souvislosti s osobností Karla Janečka. My jsme se setkali s technologickými lídry společnosti – Michalem Šaňákem a Petrem Altmanem rozhodnuti z nich vytáhnout co nejvíce o vývojářském pozadí firmy a problémech, které musí v této oblasti řešit.
Po delší přestávce jsme zavítali do kanceláří RSJ poblíž pražského Florence. Společnost se zabývá algoritmickým obchodováním na světových burzách a bylo o ní slyšet v souvislosti s osobností Karla Janečka. My jsme se setkali s technologickými lídry společnosti – Michalem Šaňákem a Petrem Altmanem rozhodnuti z nich vytáhnout co nejvíce o vývojářském pozadí firmy a problémech, které musí v této oblasti řešit. Every improvement of your development process that is performed on daily basis is worth considering and implementing. Even little things can save days in budgets if you multiply them by the count of team members and the number of operation occurrences in the year. How do you look up for classes or JSP/FreeMarker/whatever templates when you run at error in them during development or testing? In development mode you might have your logging output open in IntelliJ Idea and click through exception stacktraces if any happens to be printed there. But there are cases when it's not possible - for example errors in templates won't navigate you to the source template, logs in test / preprod environment can't be easily consumed by your IDE etc.
Every improvement of your development process that is performed on daily basis is worth considering and implementing. Even little things can save days in budgets if you multiply them by the count of team members and the number of operation occurrences in the year. How do you look up for classes or JSP/FreeMarker/whatever templates when you run at error in them during development or testing? In development mode you might have your logging output open in IntelliJ Idea and click through exception stacktraces if any happens to be printed there. But there are cases when it's not possible - for example errors in templates won't navigate you to the source template, logs in test / preprod environment can't be easily consumed by your IDE etc. Vyděsil vás titulek článku? Vlastně to bylo tak trochu cílem. Mnoho z nás totiž žije v klamné představě, že nasazení důvěryhodného SSL certifikátu a správná konfigurace webového serveru postačuje k zajištění důvěryhodného a nečitelného přenosu dat mezi serverem a klientem. Naše přesvědčení potvrzuje fakt, že na tomto předpokladu staví celý svět online byznysu.
Vyděsil vás titulek článku? Vlastně to bylo tak trochu cílem. Mnoho z nás totiž žije v klamné představě, že nasazení důvěryhodného SSL certifikátu a správná konfigurace webového serveru postačuje k zajištění důvěryhodného a nečitelného přenosu dat mezi serverem a klientem. Naše přesvědčení potvrzuje fakt, že na tomto předpokladu staví celý svět online byznysu.

 Je zajímavé, že tak základní věc, jako serializace objektů do binárního streamu je v Javě implementovaná neoptimálně - a to jak z hlediska velikosti výsledné binární podoby, tak i rychlosti s jakou je vytvořena. Míst, kde se serializace objektů hodí je celá řada, a proto je určitě v zájmu každého kvalitního vývojáře zamyslet se, jestli to nejde dělat líp.
Je zajímavé, že tak základní věc, jako serializace objektů do binárního streamu je v Javě implementovaná neoptimálně - a to jak z hlediska velikosti výsledné binární podoby, tak i rychlosti s jakou je vytvořena. Míst, kde se serializace objektů hodí je celá řada, a proto je určitě v zájmu každého kvalitního vývojáře zamyslet se, jestli to nejde dělat líp. Rather cryptic headline describes a pain many of us have to go through when restoring MySQL database backup from different machine. If you have ever done this on database with DB views - you'd probably run at this problem too.
Rather cryptic headline describes a pain many of us have to go through when restoring MySQL database backup from different machine. If you have ever done this on database with DB views - you'd probably run at this problem too. Systematické vzdělávání je pro programátory holou nutností a naše doba nám k tomu dává výjimečné příležitosti. Když jsem s programováním začínal, byl jsem rád, když mi otec sehnal od známého z PVT nějakou vysloužilou knížku o programování v Basicu - a to byl můj jediný zdroj informací. Knížka byla v angličtině a plno věcí jsem tehdy ani nepochopil. Informací bylo pomálu a řada z nich byla už tenkrát zastaralá (mluvím o roce 93). Před příchodem Internetu bylo sdílení informací a možnost vzdělávání se v IT zkrátka velmi omezené a složité.
Systematické vzdělávání je pro programátory holou nutností a naše doba nám k tomu dává výjimečné příležitosti. Když jsem s programováním začínal, byl jsem rád, když mi otec sehnal od známého z PVT nějakou vysloužilou knížku o programování v Basicu - a to byl můj jediný zdroj informací. Knížka byla v angličtině a plno věcí jsem tehdy ani nepochopil. Informací bylo pomálu a řada z nich byla už tenkrát zastaralá (mluvím o roce 93). Před příchodem Internetu bylo sdílení informací a možnost vzdělávání se v IT zkrátka velmi omezené a složité. Po roční přestávce je letos opět organizována "
Po roční přestávce je letos opět organizována "